









Introduction
Phishing is one of the most common online security threats. A phishing website tries to mimic a legitimate page in order to obtain sensitive data such as usernames, passwords, or financial and health-related information from potential victims.
Machine learning (ML) algorithms have been used to detect phishing websites, as a complementary approach to signature matching and heuristics. They usually rely on a set of “domain knowledge” features, for example, the number of days the security certificate in the header is valid, the number of domains under the certificate, the host information, etc. However, many of the domain knowledge features are not available for inline processing, and they can be easily circumvented by sophisticated attackers.
To address the shortcomings of the domain knowledge features and detect zero-day phishing attacks in real time, at Netskope we use the latest deep learning techniques to implicitly learn the patterns of phishing websites. This includes using deep learning-based encoders on the textual content of the HTML page, Javascript and CSS code. We have been awarded three U.S. patents (Patent # 11,336,689, 11,438,377 and 11,444,978) for our innovative approach to phishing detection.
HTML Encoder
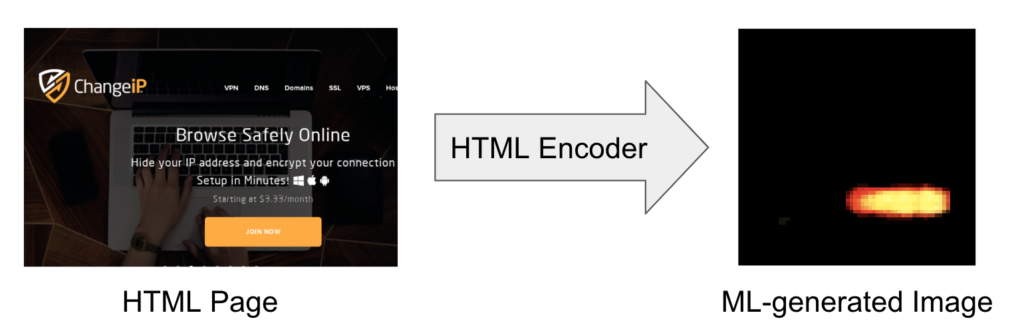
We have developed an HTML encoder to learn the proper representation of the entire HTML content (including the text body, Javascript, and CSS scripts) associated with the phishing detection use case. The HTML encoder is trained with the transformer-based deep learning architecture. This is inspired by the recent success of state-of-the-art language models, such as BERT and GPT transformer models. Similar to other transformer-based generative pre-training, we use a large number of web pages to train the HTML encoder in an unsupervised fashion. Unlike the BERT and GPT language models, however, the output of the HTML encoder is a two-dimensional ML-generated image. We chose the image output because phishing attacks are designed to use web pages that look similar to the real login pages. The ML-generated images appear to be effective in capturing features relevant to phishing and ignoring irrelevant parts of a web page. Below is an example of an HTML page and the corresponding ML-generated image from the HTML encoder.
The following GIF file shows more examples of the images generated by the HTML encoder. We should keep in mind that our objective is not to generate realistic images from the HTML content. Instead, it is to learn the suitable HTML representation that will be used to train the classification model for phishing detection.

Classification – phishing or not
Once we generate a suitable numerical representation (a vector of numbers) from the HTML content of a web page using the HTML encoder, we then combine it with the embedding of the URL string characters. The resulting numerical values are used as input features and fed into a neural network for final classification. We have collected millions of known phishing web pages and benign pages to train the binary classification model. Since we don’t keep the encoder parameters frozen, the HTML encoder will be fine-tuned toward phishing classification. The trained classifier will determine whether a new web page is phishing or not.
Netskope Threat Protection
The patented phishing website classifier is now part of Netskope Threat Protection, a comprehensive, multi-layered threat protection system powered by AI and machine learning. It enables us to block phishing web pages in real time, because it only needs the page URL string and the HTML content as input, which is readily available in the web traffic that goes through the Netskope secure access service edge (SASE) platform. The phishing classifier has the capability to detect unknown and zero-day phishing attacks, complementing other heuristic and signature-based engines. This classifier has been optimized to scan web pages inline, with an average runtime of less than 10 milliseconds.
To learn more about the multiple layers of threat capabilities that deliver comprehensive threat protection for cloud and web services, please visit Netskope Threat Protection.
The authors would like to acknowledge the significant contributions from Senior Research Scientist Najmeh Miramirkhani on this project.

