









Over a decade ago, when cloud-delivered security services like secure web gateway (SWG) began emerging, the focus was mainly on protecting a small segment of the workforce—remote users plus contractors, suppliers, and partners. The challenge was ensuring these off-premises users had the same security protections as those on-site, especially when endpoint agents were insufficient, impractical, onerous, or prone to being disabled! At that time, many high-profile enterprises—for example in banking and financial services—also considered cloud services as a backstop in case of dreaded “black swan” events. For example, extreme weather events like Hurricane Helene or Hurricane Milton, or unexpected crises such as civil unrest, terror attacks, or war, could take an entire data center or head office offline In both cases the objective was to ensure security coverage was always in place, since security had become so integral to the business and the consequences so great if there was a gap (e.g. loss of valuable data or intellectual property, fines and penalties from non-compliance, or a negative impact on a company’s public brand and reputation).
These enterprises were ahead of their time, as we learned during the COVID pandemic, with the remote work paradigm being flipped. Today, workers will sometimes be in the office and other times working from home. It’s the norm, not the exception (and in some cases, the promise of hybrid work is even being used to aid in recruiting talent). This has obviously accelerated the adoption of cloud security services, including a security service edge (or SSE) that combines firewall, web, and SaaS security, as well as zero trust network access (ZTNA). Today, the application of cloud security extends far beyond remote workers. It now encompasses all enterprise traffic—from users, sites, and machines—routing through provider infrastructures. For providers like Netskope, this shift brings immense responsibility, but for enterprises it also unlocks major advantages related to infrastructure consolidation, cost savings, and enhanced security. Networking, Infrastructure, and Operations (NI&O) teams that have adopted Netskope have also benefited from a streamlined “direct-to-net” approach, removing latency and the performance hit that comes with it.
Now a new conundrum is manifesting itself and forcing many enterprises who have standardized on a cloud provider to re-evaluate their architecture. Because the risk of a “Black Swan” is still ever present, the enterprise expects service providers to protect them against it. In large part, service level agreements are provided as the “insurance” from the vendor that they can deliver, but it is not enough.Customers are increasingly asking the hard questions and wanting to get into the details of the providers’ architecture. They want to understand for example how Netskope has built and designed its own infrastructure to be ready to handle the unexpected—while continuing to deliver always on, always available security that is fast and with a great digital experience.
Why “Architecture Matters” with Netskope NewEdge
Early on, Netskope recognized that “architecture matters” and prioritized the right architectural approach for security traffic processing at the edge, investing more than $250M in its NewEdge infrastructure. The Netskope Platform Engineering team—composed of veterans who have built and scaled out some of the largest clouds and content delivery networks (CDNs) in the world—draw from their real-world experiences solving some of the internet’s toughest challenges. The team designed NewEdge with both performance and resilience in mind, ensuring it meets the stringent business continuity demands of enterprises. This includes a focus on more than just the end-user experience, but also an obsession with customers’ internal operations. At the end of the day, NewEdge must not create a burden for network operators. Instead, the goal is for NewEdge to simplify and improve operations, compared with previously orthogonal security solutions that forced trade-offs.
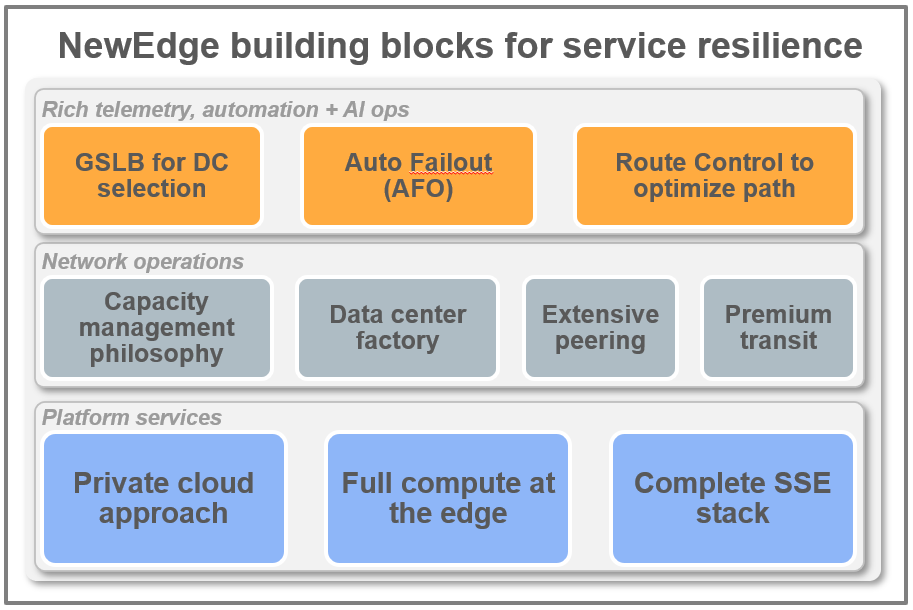
In order to deliver on this mission, the building blocks of resiliency within the NewEdge architecture begin with the sheer volume of NewEdge data centers, or “network edges,” strategically positioned across 76 regions globally, including a presence inside Mainland China. Every data center is built with complete service parity to the others, offering full compute and the complete set of SSE services in every location. The NewEdge capacity management strategy is also key to reliability and resiliency as scaling is done intentionally, well ahead of demand. Because NewEdge is built on replicable units of capacity, new capacity can be added with ease, while reducing the potential blast radius. The Netskope “data center factory” approach also ensures infrastructure consistency and enables rapid deployment of new data centers, often in just a few weeks.
The aggressive interconnection strategy of NewEdge is another critical building block. Every data center has redundant, premium transit links as well as extensive peering— in total representing more than 4,000 network adjacencies and 700 unique ASNs today. In fact, Netskope is consistently in the “top 15” organizations globally, across all industries, in terms of global IX participation. For example, Netskope aggressively peers with Microsoft, Google, Salesforce, AWS, and others at every location where there is a common interconnection point. With this focus on “connectedness” built into NewEdge, the Platform Engineering team has invested heavily in developing in-house software to maximize the use of the most highly-available and high-performing connectivity in real-time.
How NewEdge helps in the face of natural disasters and “Black Swan” events
Returning to the discussion around “Black Swan” events, Netskope has consistently demonstrated the architectural advantages of NewEdge in the face of natural disasters and other unexpected events (e.g. internet cable cuts or backbone router failures). Recently, in the wake of Hurricane Helene and prior to Hurricane Milton making landfall in the United States, aggressive actions were taken to bolster connectivity, specifically with Starlink. The Platform Engineering team predicted, with the likely impairment of critical internet resources in the affected areas, there would be a heightened usage of Starlink service. As evidence of the connectivity changes was quickly implemented over a 48-hour period, on October 7th only 16% of outbound traffic from NewEdge data centers to the Starlink network were sent through direct connections, while after the deployment and by October 9th, that number grew significantly to 96%! This allowed Netskope customers to leverage the strengths of the Starlink backbone for reliable, low-latency routing to the nearest NewEdge data center and onward to their ultimate destination (web, cloud, SaaS or private app)—all while maintaining their critical security coverage.
The story doesn’t end there though. At Netskope, we obsess over identifying and remediating problems before our customers are impacted or have to open a support ticket. This requires that we think about more than “traditional” monitoring when it comes to understanding the health of our services and infrastructure. Accordingly, the Platform Engineering team has developed and deployed extensive synthetic (in addition to real-time) monitoring which seeks to replicate user experience instead of relying on devices (or our customers) to tell us whether they’re healthy or not. Additionally, we collect and analyze endpoint and network telemetry data to automatically tune and improve NewEdge performance, as well as react when unexpected events occur. For example, underpinning the decision of which data center a user will connect to is intelligence that factors in not only the nearest, but also the best performing and lowest latency on-ramp. At the same time, the Netskope Client is aware of up to ten nearby data centers, so if there is a network glitch or unplanned maintenance, that user will be connected in seconds to the next best data center.
Leveraging this rich client and network telemetry data, event correlation and automated actions can then be taken quickly within NewEdge and often in a fully-automated fashion (aka without “hands on keyboards”). For example there have been numerous regional cable cuts this year—including a major event in March with the West Africa Cable System, MainOne, South Atlantic 3, and ACE sea cables—whereby auto failout of a specific data center was necessary based on suboptimal performance and triggers like high latency, packet loss, or jitter being identified. Of course in this instance with the aforementioned NewEdge Traffic Management 2.0 technology for data center selection (also known as GSLB), users were automatically reconnected (to the next best data center) with no service disruption.
There still remains the problem of other connectivity issues in a region–well outside of Netskope control—that cannot be solved by failing out a data center, nor do they necessitate such bold measures being taken. This is where a final building block for NewEdge resilience comes into play with Route Control, which is already in the process of being rolled out across NewEdge globally. This technology kicks in to enable dynamic selection and prioritization of optimized routes for end-to-end performance, for example between two data centers as part of a ZTNA deployment or to optimize performance to an internet or cloud destination. The selection of premium transit and an aggressive interconnection strategy mentioned earlier in this blog, play a key contributing role alongside Route Control. Ultimately, real-time analysis of routes combined with automation ensures performance and resilience at all times, to essentially identify and route around congestion or connectivity issues—events well outside Netskope control—even micro-outage events that only last for a few minutes.
Conclusion
Going forward and building on the unique innovations that are only possible with a private cloud approach, the Platform Engineering team at Netskope will continue to actively embrace “AI-ops” for an anomaly-based, predictive approach to how it operates the NewEdge infrastructure. This will further enrich the building blocks of resiliency that make up NewEdge and the Netskope approach to business continuity. And will give customers, especially NI&O teams, further confidence sending their traffic over NewEdge, viewing it as an extension of their own enterprise network, architected to handle the next hurricane or feared “black swan” event that might be on the horizon.
To learn more about Netskope, its industry-leading SSE, the NewEdge private cloud, or get connected with a member of the Netskope Platform Engineering team, please visit: https://www.netskope.com/newedge.

