

























In AWS, there are two ways to log access to S3 storage resources, i.e. buckets and bucket objects:
- server access logging (https://docs.aws.amazon.com/AmazonS3/latest/dev/ServerLogs.html)
- bucket object-level logging using CloudTrail (https://docs.aws.amazon.com/AmazonS3/latest/user-guide/enable-cloudtrail-events.html)
However, understanding the differences and how to configure each one can be confusing and complex. In this blog, we’ll explore the functionality and caveats of both and why you would want to use one versus the other.
Server Access Logging
Server Access Logging is similar to http server logging in the kind of information logged. It answers the general question, “Who is making what type of access to which objects?” Server access logging has several limitations that make it a non-starter for production IT/security needs, but is straight-forward to understand and configure.

Figure 1. Server Access Logging Architecture
In the flow above, a PDF file is written to the bucket with a CLI or API command. Server Access Logging generates one line per bucket operation and writes it to a text log file that is uploaded to an S3 log bucket that you specify when you configure server access logging. The logged information is from the perspective of the “server,” which you can associate with the public REST API endpoint on the AWS side. The formatting is loosely-structured with a known ordering of fields, space-delimited, with quote escaping for fields containing spaces. You can use S3 features in the logging bucket to configure data retention for the logs and must build your own notification system for events of interest or to analyze the log file records.
Logged Operations
Server access logging provides records of the requests that are made to a bucket. Each access is recorded as one text record with the exception of a copy (which is recorded as a delete and write). Each log entry has 24 fields that fall into 4 general categories:
- HTTP/REST operation (e.g. GET, PUT, POST, OPTIONS, etc.)
- Requester information (including user agent, AWS account, IP)
- Resource (bucket or bucket object)
- Session information (such as data size, response times, authentication type).
The information logged summarizes the access operation but does not necessarily provide full payload details. For example, a server access log entry for a PUT ACL operation on an object does not include the new ACL definition.
Example
Here is an example entry with some of the more useful fields highlighted:

Figure 2. Server Access Logging Entry
Fields
The data fields are described in the AWS documentation (https://docs.aws.amazon.com/AmazonS3/latest/dev/LogFormat.html) and summarized in this table along with example requests:
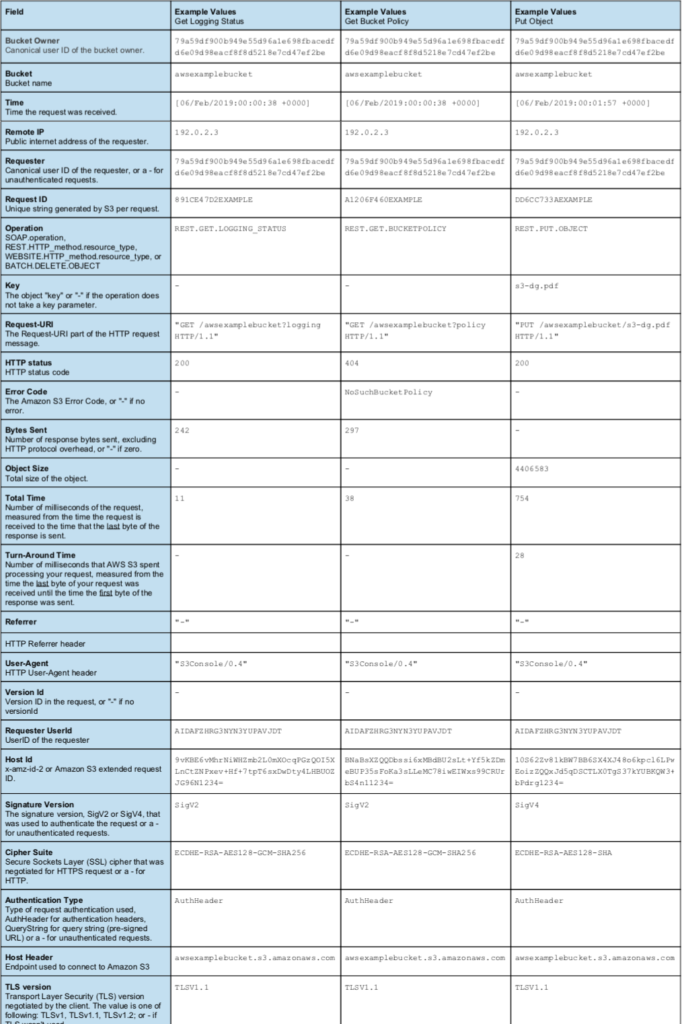
Since the fields are space delimited with double-quote escapes, a common way to parse these records for analysis or eventing will be to use regular expression parsing. In order not to mis-parse the data, care must be taken to accommodate the range and type of values for each field since fields have been added as recently as the past 12 months.
Note as well that S3 server access logging is a bucket-level configuration, meaning that certain bucket operations will not be captured such as bucket listings (which is against the S3 service itself) and bucket creation and deletion. This is in contrast to S3 Object-Level Logging with CloudTrail which can record all API calls regardless of the state of any individual bucket.
Configuration
- The AWS Console will show the Server Access Logging option during bucket provisioning/creation:

Figure 3. Server Access Configuration During Bucket Creation
- The server access logging setting is fully accessible from the AWS CLI and REST API.
- The Log Delivery group is used by the server access logging facility when writing to the S3 Log Bucket, so the S3 Log Bucket ACL should grant the Log Delivery group write access.
Object-Level Logging (CloudTrail)
Object-Level Logging, sometimes referred to as S3 CloudTrail logging, saves events in json format in CloudTrail, which is AWS’s API-call eventing service. Once in CloudTrail, detailed events are stored in an S3 Bucket, and can be easily integrated with other services such as CloudWatch (monitoring/alerts), SNS (notifications), SQS (queues for other processing), and lambda functions (serverless processing). Object-Level Logging is more complicated to understand and configure and has some additional costs, but provides advanced functionality to address all logging use cases.

Figure 4. Object-Level Logging (CloudTrail) Architecture
In the flow above, you can see that Object-Level logging involves more services than server access logging, specifically:
- CloudTrail (for recording API call events) and typically,
- CloudWatch (for notifications, alarms, and metrics)
When any bucket operation is performed, a more detailed and structured event (json format) is generated in CloudTrail, which is configured to store the event data in an S3 Log bucket. For notifications, CloudWatch is typically used as it has rich filtering functionality for matching specific events and can generate metrics with alarms and notifications targeting SNS, SQS, or lambda functions. Retention has to be configured both in CloudWatch as well as the S3 Log Bucket.
Logged Operations
All bucket API calls, both at the bucket level and object level, can be logged, including:
- Buckets: GET,PUT,DELETE on bucket, cors, encryption, lifecycle, policy, replication, tagging, versioning, etc.
- Objects: GET,DELETE,PUT,POST,HEAD on object, acl, tagging, part, multipart, torrent, etc.
In contrast to server access logging, you can see full details about operations such as PUT ACL on an object, including the ACL definition.
The list of APIs that are logged are documented in the CloudTrail documentation: (https://docs.aws.amazon.com/AmazonS3/latest/dev/cloudtrail-logging.html), but note that is out-of-date and lags behind the actual APIs offered. A detailed table follows later in the Comparison section that includes a complete API list and compares which operations are logged with object-level logging vs. server access logging.
Example
Any access to the bucket or bucket object is logged in a detailed json data structure on an S3 bucket of your choosing. Here is an example entry:

Fields
Many of the json event fields are similar to the server access log file fields but with additional detail and are described here in the AWS documentation: https://docs.aws.amazon.com/awscloudtrail/latest/userguide/cloudtrail-event-reference-record-contents.html
Configuration
- Object-Level Logging is presented as an option during bucket creation and enabled logging for this bucket’s objects only.

Figure 5. Object-Level Logging Configuration During Bucket Creation
- However, object-level logging is really a CloudTrail configuration, so it is better configured on the CloudTrail side, where it is easy to configure logging for all S3 buckets, distinguish between logging of data and/or management events, configure storage parameters for CloudTrail, and configure CloudTrail integration with CloudWatch.

Figure 6. CloudTrail Configuration for S3 API Calls (Object-Level Logging)
- Object-level logging configuration is fully accessible from the AWS CLI and REST API via the CloudTrail service.
Comparison
The most important differences between server access logging and object-level logging are summarized below.
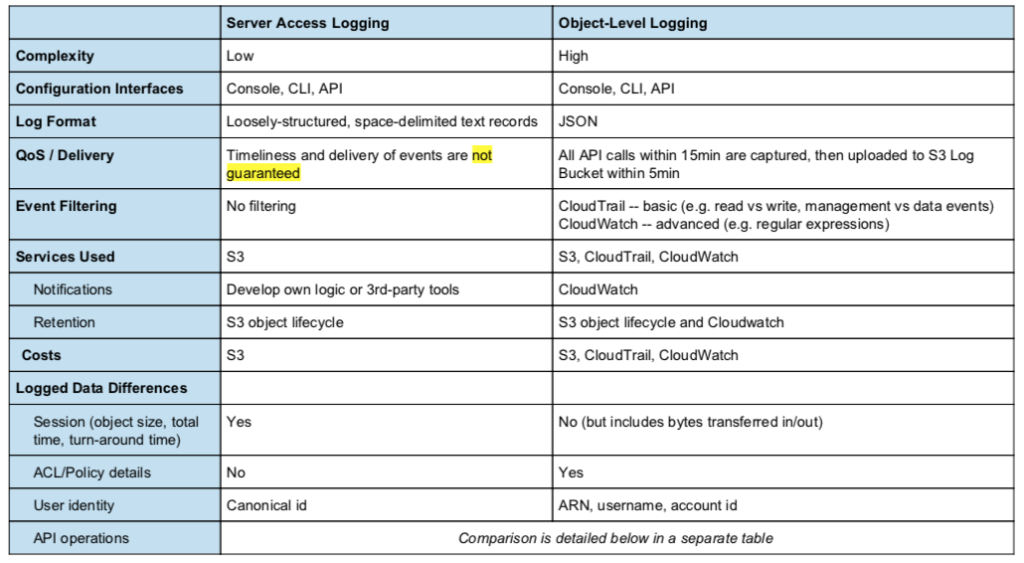
The following table provides a complete mapping between REST actions, SDK, CLI, and the actual field values seen in object-level (CloudTrail) and server access logs. Understanding this level of detail is important for actual implementation of logging and alerts. To drive reliable and complete alerting and accurate analytics, one needs to know definitively the field names and values that appear in the logs. Unfortunately, the CloudTrail documentation is incomplete and omits some API calls and server access logging blog posts often do not include the latest fields.
API Operations and Logging Field Values
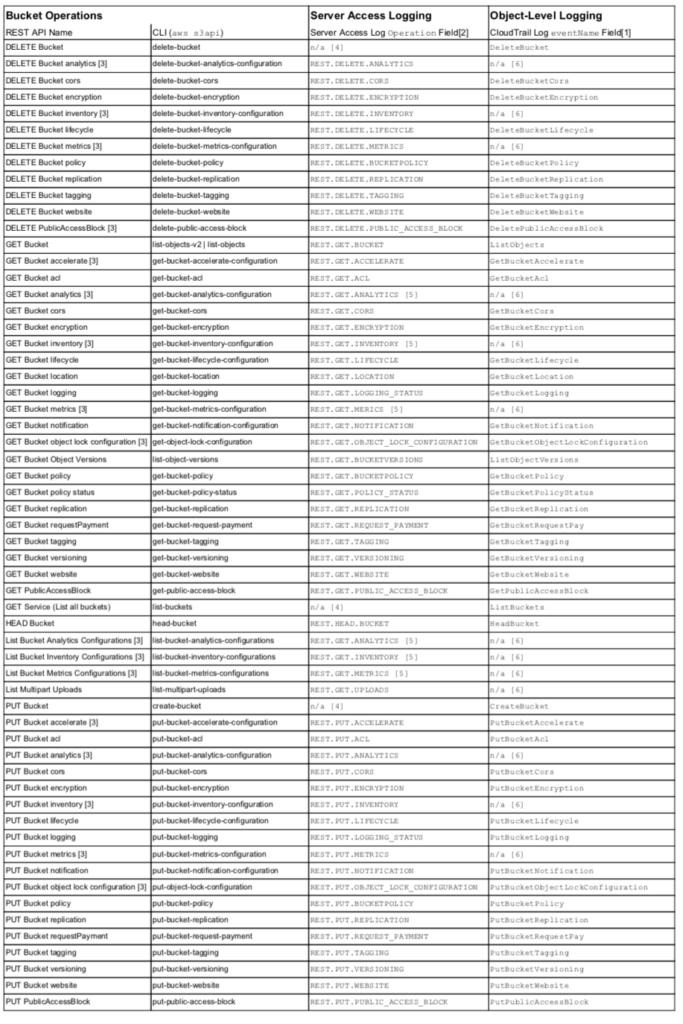
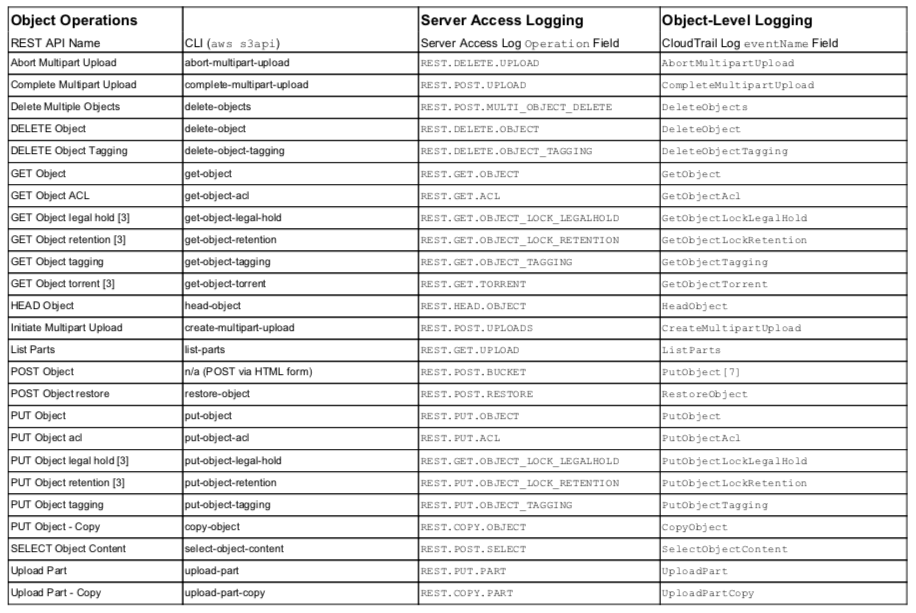
Notes:
- Additional relevant Fields for Object-Level Logging: requestParameters.*, additionalEventData.*, and resources.*
- Additional relevant Fields for Server Access Logging: bucket, key (object path), list-type
- Missing from AWS CloudTrail documentation on fields https://docs.aws.amazon.com/AmazonS3/latest/dev/cloudtrail-logging.html.
- Not available in server access logging
- requesturi parameter, id, differentiates between List and Get. Inclusion of ‘id’ indicates a Get, while no ‘id’ indicates a List.
- Not available in object-level logging
- Documentation is incorrect, lists PostObject but is PutObject.
In addition to the eventName and operation fields, both types of logging utilize other fields as indicated with footnotes [1] and [2]. Server access logging is enabled at the bucket level, so it will not record API calls that deal with the s3 service or at a meta-bucket level e.g. List Buckets, Delete Bucket, or Create Bucket as indicated by footnote [4]. Object-level logging currently omits API calls relating to Metrics, Inventory, and Analytics, indicated with footnote [3], although it is likely a temporary lag in coverage. The CloudTrail documentation is out-of-date and does not list all API calls; these are indicated in the table with footnote [3]. The CloudTrail documentation is incorrect with respect to a browser POST upload and the logged operation is a PutObject, not PostObject, and indicated with footnote [7]. Server access logging naming can be non-intuitive, so if you were to do your own eventing, the table should help. Some operation field values are the same between List and Get API calls and the differentiation comes with the existence of a request parameter, id, as indicated with footnote [5].
Server access logging is similar to old-school web server access logs–easy to set up but harder to make an effective part of IT/security operations. It’s more straight-forward in concept and practice in that it logs information in a simple text format and log file, stored in an S3 log bucket. It does not include full fidelity of access operations e.g. for a PUT of an object ACL, the ACL details are not logged. It does not guarantee logging timeliness and events can be lost (https://docs.aws.amazon.com/AmazonS3/latest/dev/ServerLogs.html#LogDeliveryBestEffort).
Generating alerts related to events of interest requires investment in utilizing 3rd-party log search tools or SIEMs or creating your own parsing/matching/notification system. Server access logging will record server-related information such as size of object/request and response times, which can be useful for capacity and performance planning.
Object-level logging utilizes the general CloudTrail API-logging/event service, which in turn provides integration with CloudWatch for advanced notifications, metrics, and alarms. All event data is stored in a JSON format. The focus on API calls means that full fidelity of data is included such as the ACL definition in a PUT operation. API calls are guaranteed to generate events within 15 minutes, and logged in your S3 log bucket 5 minutes after that. Designed to work with CloudTrail and CloudWatch, object-level logging can leverage those services for robust enterprise logging, alerting, and metrics tracking. Additional costs beyond S3 have to be planned for CloudTrail and CloudWatch.
Conclusion
Unfortunately, which logging method to use is far from clear based on common wisdom in the community. The CIS AWS Foundations Benchmark v1.1 recommends enabling server access logging for your CloudTrail S3 bucket, while some AWS documentation confusingly states:
“We recommend that you use AWS CloudTrail data events instead of Amazon S3 access logs. CloudTrail data events are easier to set up and contain more information.” https://docs.aws.amazon.com/AmazonS3/latest/dev/using-s3-access-logs-to-idenitfy-sigv2-requests.html
However, it should be clear that server access logging cannot be used for any production security or IT scenario because of several crucial limitations:
- does not guarantee delivery of data (timing not guaranteed and it can lose events)
- does not log meta-level operations such as bucket deletion and listing
- does not log full fidelity of configuration information on PUT operations e.g. ACLs
- is hard to parse reliably
- requires additional work to generate actionable alerts
The major concern is that server access logging does not guarantee delivery of events and provides less information if it does deliver an event. During normal usage and testing, it is typical to have events appear in logs hours after the event occurred or to not receive any events at all, which makes testing a challenge and more importantly, means that one cannot rely on detecting security threats based on server access logging. No security or IT professional can or should put in production any logging solution with those constraints.
Instead, object-level logging using CloudTrail should be used for all production security and IT operations. Although, it currently omits a few API calls related to metrics, inventory, and analytics, these are a temporary gap in coverage as CloudTrail is the preferred method from AWS for logging of API calls. CloudTrail-based logging is superior in every manner and provides a reliable, logging of API calls, not just for S3 operations, but for most services. Combined with CloudWatch, it provides enterprise-level eventing, logging, notifications, and metrics tracking with flexible filtering rules and full data fidelity captured in structured JSON for straight-forward and reliable analytics.
Since logging is fundamental to many security operations workflows such as auditing, forensics, incident handling/response, SOC monitoring, eventing/alerts, reports, and analytics, you should understand the logging options available, and hopefully, this information has helped you in that regard. The next step is putting effective logging into practice in your environment.
To assist you in these efforts, Netskope provides:
- Continuous Security Assessment checks that can automatically detect whether logging is enabled properly and flag common misconfigurations, including checks from the Center for Internet Security’s AWS Foundation Benchmark and other best practices.


