Introduction
Machine learning-based data loss prevention (DLP) file classifiers provide a fast and effective way to identify sensitive data in real-time, empowering organizations with granular, real-time DLP policy controls. Netskope Advanced DLP offers a wide range of predefined file classifiers, such as passports, driver’s licenses, checks, payment cards, screenshots, source code, tax forms, and business agreements. Although these predefined classifiers are remarkable in their own right, they are necessarily somewhat generic when considering the enormous diversity of sensitive data across different industries and organizations. To better address company-specific or industry-specific documents, including identity documents, HR files, or critical infrastructure images, Netskope has developed a novel patented approach that allows customers to train their own classifiers while maintaining data privacy. This innovation enables organizations to focus on protecting their most critical information.
This training process, known as Train Your Own Classifier (TYOC), is designed to be efficient, requiring neither a large amount of labeled data nor time-consuming training of a supervised classification model.This capability is made possible through the use of cutting-edge contrastive learning techniques. Customers can upload a small set of example images (approximately 20-30) to the Netskope Security Cloud. These examples are then used to extract important attributes and train a customized classifier using Netskope’s machine learning engine.
Once the custom classifier is trained, it is deployed into the customer’s own tenant to detect sensitive information anywhere they use Netskope DLP including email and Endpoint DLP. Importantly, the original samples are not retained and the trained classifier is not shared with any other customers, ensuring the protection of the customer’s sensitive data throughout the process.
Image Similarity and Contrastive Learning
TYOC solves a problem of image similarity by using techniques of contrastive learning.
Image similarity addresses the challenge of identifying images that resemble a reference image, even when there are minor differences in aspects such as color, orientation, cropping, and other characteristics. This process can be effectively managed using advanced contrastive learning techniques.
Contrastive learning is designed to extract meaningful representations by contrasting pairs of similar (positive) and dissimilar (negative) instances. It is based on the concept that similar instances should be positioned closer in a learned embedding space, whereas dissimilar instances should be placed further apart. Contrastive learning involves training image models through unsupervised learning by augmenting each image in a manner that preserves its semantic content. This augmentation includes operations such as random rotations, color distortions, and crops, ensuring that the cropped area remains a significant portion of the original image. These augmented samples are used to train a convolutional neural network (CNN)-based image encoder model. This encoder takes an image as input and produces a feature vector, also known as a representation or embedding.
Netskope TYOC combines a pre-trained image encoder built by Netskope with a small number of training images provided by a customer. The combination enables the Netskope security cloud to perform image similarity ranking on customer-relevant files with performance similar to what is achieved by built-in (predefined) file classifiers.
Training with Contrastive Learning
The encoder model learns to identify similarities between images by establishing that matched pairs of images, referred to as positive pairs, exhibit the highest similarity. Conversely, unmatched pairs or negative pairs – drawn from the remainder of the image dataset – are assigned the lowest similarity. We illustrate this concept through examples of positive and negative pairs below.


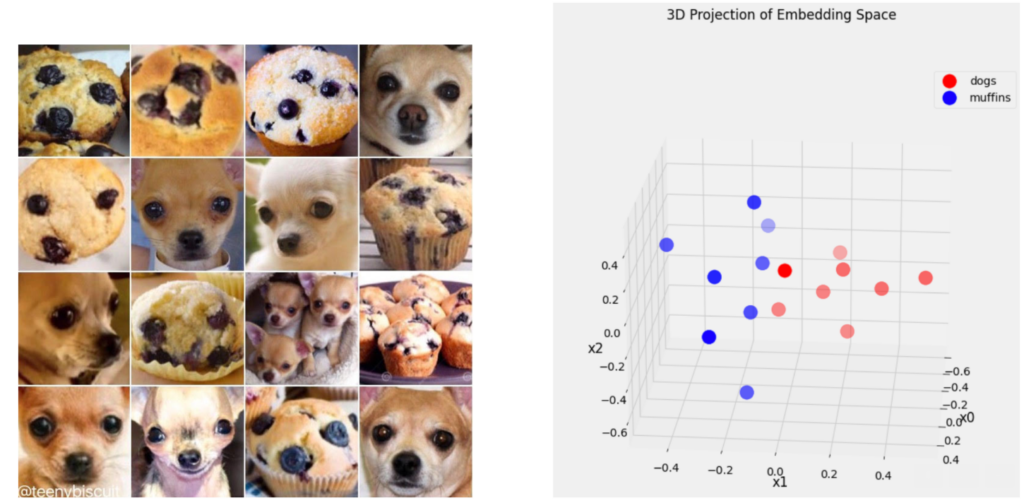
The image encoder, trained with contrastive learning, maps any image to a high-dimensional embedding for semantic hash, effectively capturing the semantic meaning of the image. The illustration below showcases the application of this pre-trained image encoder on the “Dogs & Muffins” dataset, which comprises eight images of dogs and eight images of muffins, all closely resembling one another in appearance. On the right, we present a three-dimensional projection of the high-dimensional embeddings generated for each image. This visualization clearly demonstrates the distinct segregation of the two categories within the embedding space, underscoring the encoder’s efficacy in capturing and differentiating the semantic essence of the images.
Using Train Your Own Classifier
By utilizing the pre-trained image encoder model, our system allows customers to upload their training or reference images for the purpose of training a bespoke classifier. For optimal performance, it is recommended to provide at least 20-30 reference images for each category. The image encoder processes these reference images, converting them into high-dimensional embeddings. To ensure privacy, the original images are deleted after encoding. These reference embeddings are then utilized to construct an Approximate Nearest Neighbors (ANN) index, which acts as the custom classifier.
During the inference phase, new images undergo encoding to generate embeddings using the same image encoder model. The ANN model then identifies the class label of the nearest reference embedding. If the distance to this nearest embedding falls below a predefined threshold, the image is assigned the corresponding predicted label from the reference embedding. If not, the image is categorized under the predicted label “other.”

Case Studies
Access Cards
In this evaluation, we adopted the TYOC methodology for classifying Access Cards, as detailed below. Initially, our dataset comprised only three authentic (sample) examples, illustrated on the left side. To augment our training data, we generated 30 synthetic images. This augmentation involved substituting the portraits on the sample cards with a variety of random portraits, as depicted on the right side. Subsequently, we allocated 20 of these images for training the classifier, while the remaining 10, along with 1,000 randomly selected negative examples, were used for testing purposes. In the testing phase, the custom classifier demonstrated exceptional performance, achieving a recall or detection rate of 100% with the precision of 99.3%.

Handwritten Signatures
For this experiment, a public dataset of handwritten signatures was used. The dataset includes signatures of 64 individuals, with approximately 25 image instances for each name. Of these, around 10 images per name represent forgeries. All images were transformed into embeddings using the pre-trained image encoder, without any further retraining. For each individual, six embeddings were incorporated into Annoy as reference images, while the remaining approximately 20 embeddings per name served as test samples. When assessing the test images of signatures, they could be accurately matched to the corresponding name with an 87% accuracy, provided that forgeries were considered valid matches. If forgeries were excluded, the accuracy rate slightly decreased to 84%.

Privacy Concerns
Our pre-trained image encoder translates images into high-dimensional semantic embeddings – compact vector representations of an image’s essential meaning and its visually similar counterparts. As these embeddings contain semantic data, there is a theoretical risk that images could be partially or fully reconstructed from their embeddings, potentially compromising user privacy within our system.
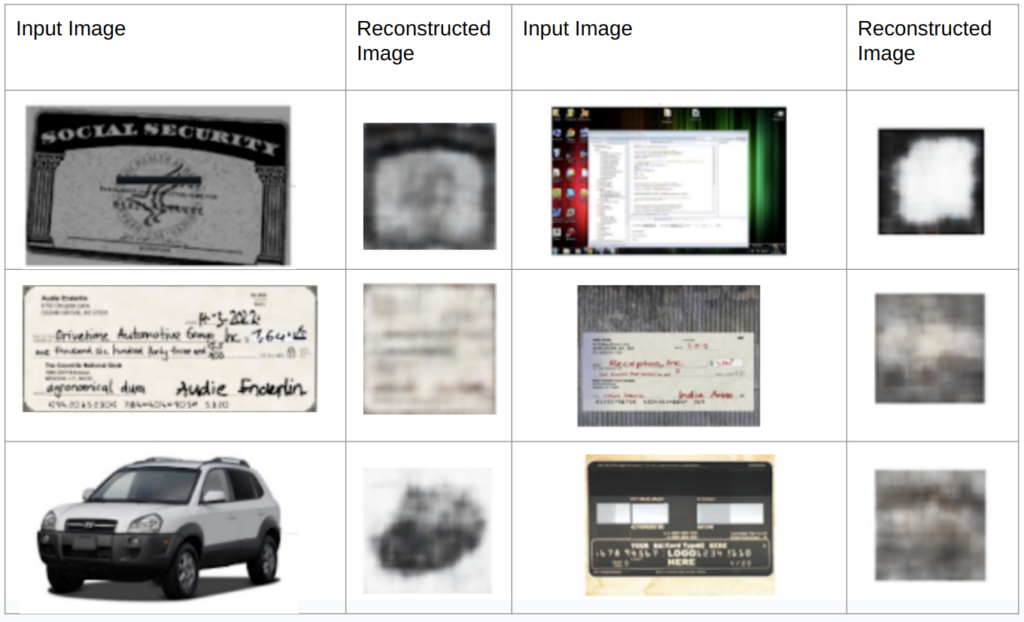
To mitigate these concerns, we’ve conducted thorough experiments and found that while it is theoretically possible for images to be reconstructed from high-dimensional embeddings under extremely unlikely situations, the resulting versions would be of very low fidelity. This limitation significantly restricts the amount of recoverable information, providing a robust safeguard against potential privacy breaches.
As a worst case scenario, we attempt to reconstruct images from their high-dimensional TYOC embeddings using a generative AI model that has access to the TYOC encoder. Below are some of the results. Although it is highly unlikely that the model architecture, weight files, and actual image embeddings would be fully accessible, our reconstructions still exhibit very poor quality, failing to reproduce any fine details.
Summary
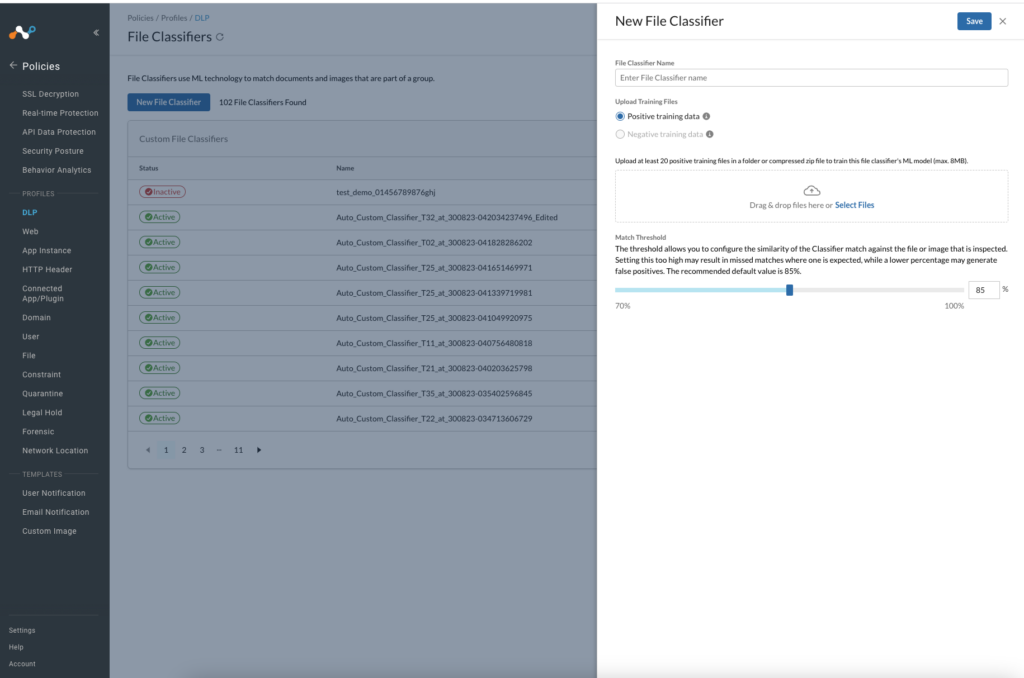
Train Your Own Classifier is now generally available as part of Netskope’s Advanced DLP (screenshot below). To learn more about the industry’s most comprehensive and most advanced cloud DLP solution, please visit the Netskope Data Loss Prevention page.