









Introduction
App connectors are a critical component of the Netskope secure access service edge (SASE) platform, offering visibility into user activities based on their interactions with cloud applications. These connectors monitor various types of user actions, such as uploads, downloads, and sharing events in apps like Google Drive and Box, by analyzing network traffic patterns. With this visibility, security administrators can then configure and enforce real-time policies to prevent malware, data theft and exfiltration.
However, app connectors may occasionally fail to detect certain activities due to factors such as app updates or network disruptions. To mitigate the impact of these issues for our customers, it’s essential to proactively detect the changes in the app behavior and alert our engineers when adjustments to the connectors may be needed. The main challenge lies in distinguishing actual app connector failures from normal fluctuations in network traffic. To address this, we’ve developed a patent-pending app activity monitoring system that leverages advanced machine learning algorithms to automatically identify significant anomalies in app event counts. This system has been fine-tuned to flag issues early, while minimizing false alerts, ensuring efficient and accurate detection of potential app connector problems.
Time series data
Hourly event counts from the app connector are collected via the data pipeline and grouped by data center, tenant, application, and activity type. No personally identifiable information (PII) is captured in this process. The time series data undergoes further aggregation, cleaning, and enrichment during feature engineering. Additional features, such as time of day, day of the week, and country-specific holiday calendars, are incorporated to account for expected fluctuations in app event counts.
Our approach
Prediction model-based time series anomaly detection is a widely used technique for identifying anomalous points in a time series by comparing the forecasted values with the actual observed values, as illustrated in Figure 1. However, maintaining forecasting models for each individual univariate time series (e.g., for each data center, app, or activity type) can be cumbersome. Additionally, univariate models fail to capture the relationships between different time series. For example, if an event count for a specific app drops simultaneously across multiple data centers, it’s more indicative of an app connector issue than a localized network problem.
Moreover, multivariate autoregressive models have also proven to be unsuitable due to the large number of parameters that need to be learned, making the model training process infeasible.
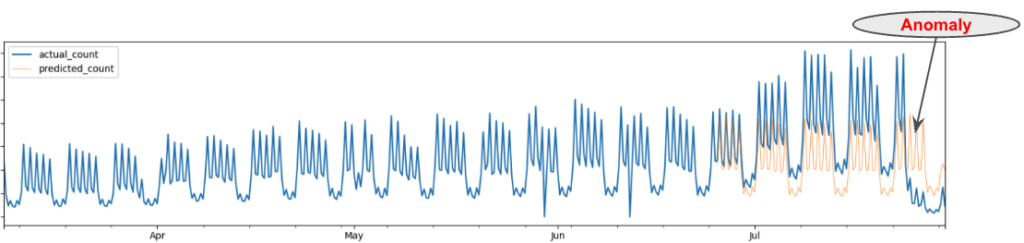
We selected the Transformer-based architecture to address the challenges of modeling multivariate time series in a unified model. Specifically, we chose the Temporal Fusion Transformer (TFT) model, which is a variation of the Transformer that supports multi-horizon, multivariate forecasting and provides interpretability through its multi-head attention mechanism. This model uses static variables (like event names) and time-varying features (like holidays), along with autoregressive lag values, to make predictions.
During the training and tuning of our anomaly detection engine, several parameters are learned in addition to the TFT model’s hyperparameters. These include the length of data history required for training, a winsorizing function, a threshold for identifying significant dips, a dip-smoothing function, and the creation of variables for unaccounted holidays or global effects (e.g., network disruptions).
The goal of tuning the anomaly detection engine is to accurately detect anomalous dips caused by app connector failures as quickly as possible, while minimizing false alarms that could lead to unnecessary investigations or wasted resources. Our aim was to balance detection accuracy, early detection, and avoiding unnecessary alerts.
Put it in action
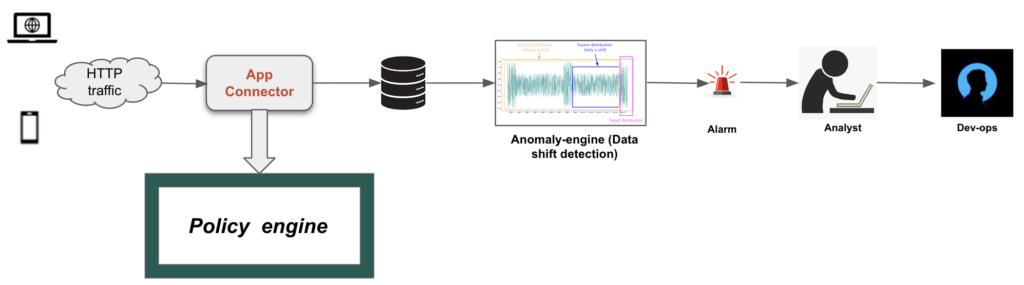
We have successfully deployed the anomaly detection engine, powered by the TFT model, to proactively monitor the health of the App Connectors. When the engine identifies anomalous dips in app event counts, it sends email alerts with key details such as:
- Time of detection
- Severity of the issue
- Visualizations showing shifts in app event counts
These alerts enable analysts to prioritize investigations and determine whether specific App Connectors require fixes. Figure 2 illustrates a common workflow. Over the past few months, this anomaly detection system has successfully identified several App Connector failures that other mechanisms missed.
The authors wish to thank Netskope’s app connector engineering team for their collaboration. We continue to work closely to enhance the accuracy and usability of the app activity monitoring system.

