















AI Securityプレイブック
このプレイブックでは、組織が AI を採用する際に直面する 6 つの主要なセキュリティ課題と、それらに対処するための実証済みの現実世界の戦略について説明します。

Netskopeプラットフォームを実際に体験する
Netskope Oneのシングルクラウドプラットフォームを直接体験するチャンスです。自分のペースで進められるハンズオンラボにサインアップしたり、毎月のライブ製品デモに参加したり、Netskope Private Accessの無料試乗に参加したり、インストラクター主導のライブワークショップに参加したりできます。
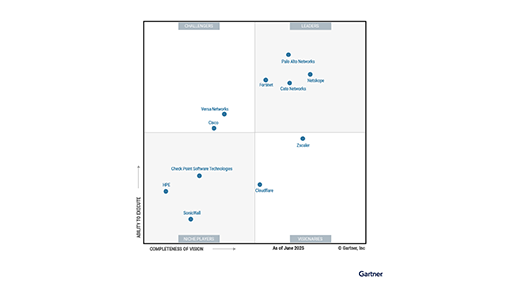
Netskope は、 SSE プラットフォームと SASE プラットフォームの両方で、ビジョンで最も優れたリーダーとして認められています
2X ガートナーマジック クアドラント SASE プラットフォームのリーダー
旅のために構築された 1 つの統合プラットフォーム
旅のために構築された 1 つの統合プラットフォーム

Netskope One AI Security
ビジネスを加速させるために、AIの安全な活用は不可欠です。とはいえ、制御やガードレールのせいでスピードやユーザー体験が損なわれては本末転倒。Netskopeは、お客様がAIのメリットを最大限に引き出せるよう支援します。
Netskope One AI Security
ビジネスを加速させるために、AIの安全な活用は不可欠です。とはいえ、制御やガードレールのせいでスピードやユーザー体験が損なわれては本末転倒。Netskopeは、お客様がAIのメリットを最大限に引き出せるよう支援します。



リスクがどこにあるかを理解する
Advanced Analytics は、セキュリティ運用チームがデータ主導のインサイトを適用してより優れたポリシーを実装する方法を変革します。 Advanced Analyticsを使用すると、傾向を特定し、懸念事項に的を絞って、データを使用してアクションを実行できます。

ユニバーサルZTNAがVPNとNACの混乱から抜け出す賢い方法である6つの理由
VPN と NAC の複雑さを解消します。Universal ZTNA が 1 つの一貫したフレームワークですべてのユーザーとデバイスを保護する方法を学びます。


The Lens

Netskopeのチームからの最新ニュースと意見を読む。 「ザ・レンズ」は、当社のブログ、ポッドキャスト、ケーススタディを統合したもので、毎週新しいコンテンツが追加されます。

Netskopeテクニカルサポート
クラウドセキュリティ、ネットワーキング、仮想化、コンテンツ配信、ソフトウェア開発など、多様なバックグラウンドを持つ全世界にいる有資格のサポートエンジニアが、タイムリーで質の高い技術支援を行っています。

AI in the Fast Lane Roadshow
Netskopeの「AI in the Fast Lane」ロードショーでは、セキュリティ専門家が一堂に会し、組織がどのようにして 今日のAIを活用しているか、そして包括的なセキュリティ戦略によって、よりスマートで安全、かつ将来性のあるモデルをどのように構築できるかについて議論します。

Netskopeトレーニング
Netskopeのトレーニングは、クラウドセキュリティのエキスパートになるためのステップアップに活用できます。Netskopeは、お客様のデジタルトランスフォーメーションの取り組みにおける安全確保、そしてクラウド、Web、プライベートアプリケーションを最大限に活用するためのお手伝いをいたします。

NetskopeビジネスバリューサービスでSASEのROIを最大化
ROI の証明を開始します。 Netskope BVSは、SASE変革による財務面および戦略面への影響を定量化する無料のコンサルティングサービスです。












