- 企業におけるAIアプリの利用は指数関数的に増加しており、過去2カ月間で22.5%増加しています。
- ChatGPTは企業で最も人気のあるAIアプリであり、Google Bardは企業で最も急速に成長しているAIアプリであり、どちらも大きな差をつけています。
- ソースコードは、他のどの種類の機密データよりも多くChatGPTに投稿されており、その割合は企業ユーザー10,000人あたり月間158件の割合です。
- 攻撃者は、ChatGPTを取り巻く誇大広告を利用しようと、AIアプリ詐欺やフィッシングサイトを作成しています。
- DLPとユーザーコーチングは、企業が機密データの露出を防ぎながらAIアプリの使用を可能にするために使用する最も一般的なタイプの制御です。

Netskopeプラットフォームを実際に体験する
Netskope Oneのシングルクラウドプラットフォームを直接体験するチャンスです。自分のペースで進められるハンズオンラボにサインアップしたり、毎月のライブ製品デモに参加したり、Netskope Private Accessの無料試乗に参加したり、インストラクター主導のライブワークショップに参加したりできます。
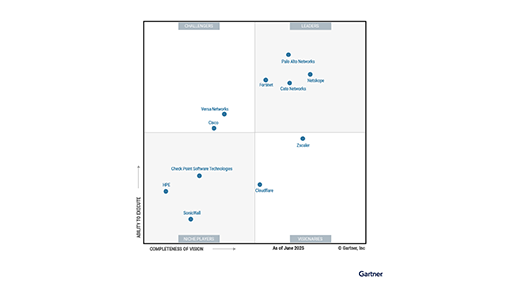
Netskope は、 SSE プラットフォームと SASE プラットフォームの両方で、ビジョンで最も優れたリーダーとして認められています
2X ガートナーマジック クアドラント SASE プラットフォームのリーダー
旅のために構築された 1 つの統合プラットフォーム
旅のために構築された 1 つの統合プラットフォーム

リスクがどこにあるかを理解する
Advanced Analytics は、セキュリティ運用チームがデータ主導のインサイトを適用してより優れたポリシーを実装する方法を変革します。 Advanced Analyticsを使用すると、傾向を特定し、懸念事項に的を絞って、データを使用してアクションを実行できます。

レガシーVPNを完全に置き換えるための6つの最も説得力のあるユースケース
Netskope One Private Accessは、VPNを永久に廃止できる唯一のソリューションです。

Netskopeテクニカルサポート
クラウドセキュリティ、ネットワーキング、仮想化、コンテンツ配信、ソフトウェア開発など、多様なバックグラウンドを持つ全世界にいる有資格のサポートエンジニアが、タイムリーで質の高い技術支援を行っています。

Netskopeトレーニング
Netskopeのトレーニングは、クラウドセキュリティのエキスパートになるためのステップアップに活用できます。Netskopeは、お客様のデジタルトランスフォーメーションの取り組みにおける安全確保、そしてクラウド、Web、プライベートアプリケーションを最大限に活用するためのお手伝いをいたします。

Netskope One SSEでビジネス価値を達成する
Netskope One Security Service Edge(SSE)は、ビジネスクリティカルなセキュリティサービスを Netskope One プラットフォームに統合することで、企業が大きなビジネス価値を達成できるようにします